Data Engineer Mülakatında AI Desteği: SQL, Pipeline ve Spark için Gerçek Zamanlı Rehber
Data engineer mülakatları aynı anda beş alanı sınar. AI mülakat araçlarının bildiğiniz ile baskı altında söyleyebildiğiniz arasındaki uçurumu nasıl kapattığını öğrenin.
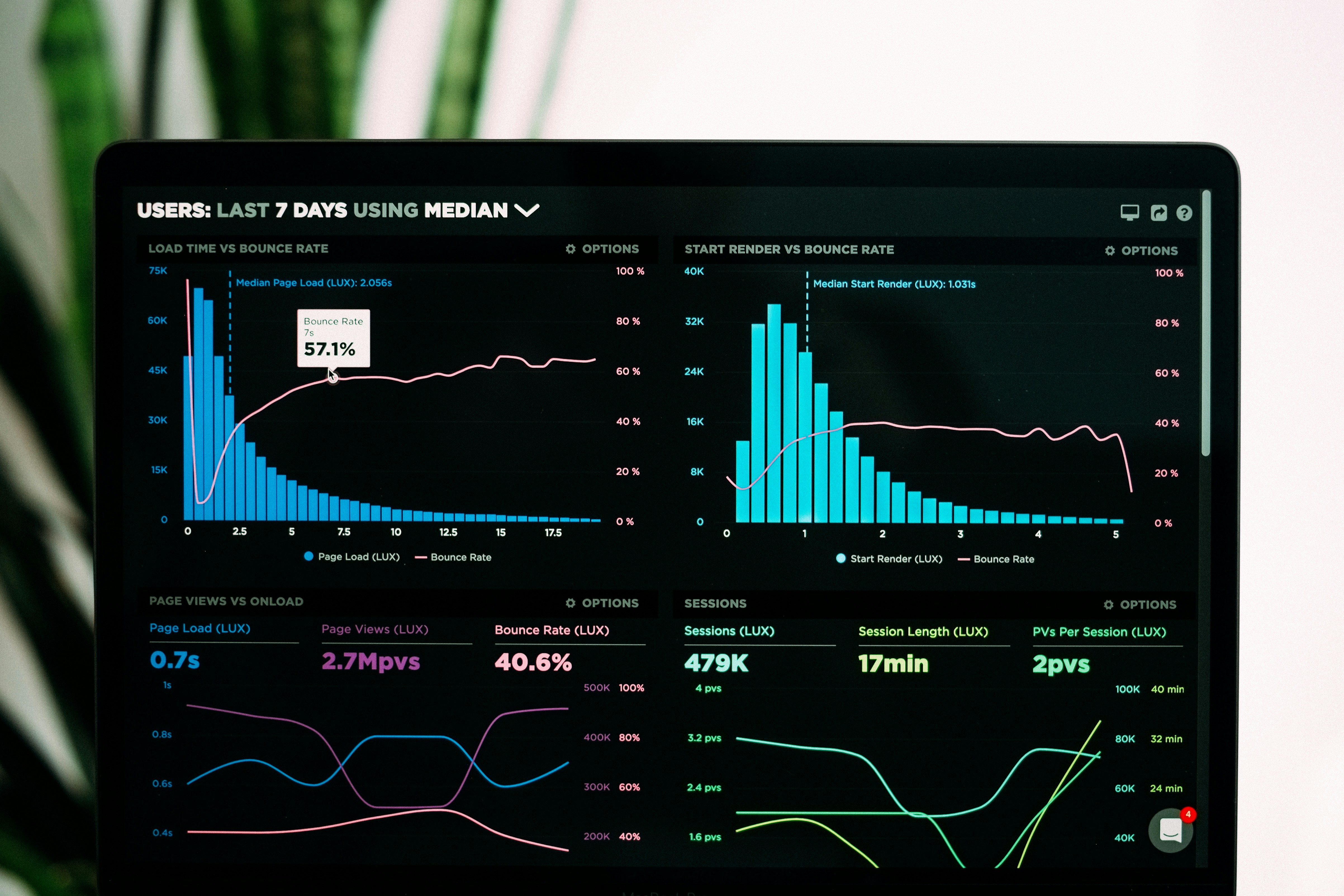
Özet: Data engineering mülakatları SQL, pipeline mimarisi, Spark performans ayarı, dbt modeling ve davranışsal senaryoları tek bir döngüde sınar. Hazırlık kaynaklarının büyük çoğunluğu her alanı ayrı ayrı ele alır — ancak gerçek mülakat öyle yapmaz. AI mülakat araçları; bildiğiniz ile bir kıdemli mühendis beklerken ve incremental ETL tasarımında zihninizdeki bilgiler dağılırken söyleyebildiğiniz arasındaki boşluğu kapatır.
Son şirkette 300TB Spark pipeline'ı siz inşa ettiniz. Window function'ları gözleriniz kapalı yazabiliyorsunuz. Ama bir staff engineer'ın karşısında 45 dakikalık video mülakatına oturun; "streaming pipeline'ınızda late-arriving data'yı nasıl ele alırsınız?" sorusuyla yüzleşin — ve aniden tüm ayrıntılar uçup gider.
Bu bir bilgi açığı değil — performans açığıdır. Ve AI mülakat araçlarının dengeleri değiştirdiği yer tam da burasıdır.
SQL, tüm data engineer iş ilanlarının %69–79'unda yer almaktadır. Apache Spark, framework gereksinimleri arasında %38.7 ile birinci sıradadır. dbt ise niş bir araç olmaktan çıkarak günümüzde çoğu modern data stack'te bir işe alım filtresi hâline gelmiştir.
Türkiye'de Trendyol, Getir ve Hepsiburada gibi yerli teknoloji şirketleri ile Kariyer.net ve LinkedIn üzerinden başvurulan Avrupa ve ABD'deki uzaktan pozisyonlar, bu beş alanın tamamında güçlü adaylar aramaktadır.
Data Engineering Mülakat Soruları Gerçekte Neyi Kapsıyor?
Tipik bir data engineering mülakat döngüsü beş alanı kapsar:
1. SQL ve veri modelleme — Window functions, CTEs, yavaş değişen boyutlar (SCD), sorgu optimizasyonu. Klasik SCD Type 2 sorusu, yalnızca hazır pattern kullanmış mühendisleri çoğunlukla yanıltır.
2. Pipeline mimarisi ve ETL/ELT — Incremental vs. full load, schema evolution, idempotency, late-arriving data, partition stratejileri.
3. Dağıtık hesaplama — Spark performans ayarı, data skew, OOM hataları, broadcast joins, shuffle işlemleri.
4. Modern araçlar — dbt modelleri, Airflow DAG tasarımı, Kafka consumer groups, Delta Lake veya Iceberg, bulut servisleri (BigQuery, Redshift, Snowflake, Databricks).
5. Davranışsal ve sistem tasarımı — Production olayları, data contracts ve migration planlaması hakkında STAR formatında senaryolar.
Data Engineer için SQL Mülakatı: Temellerin Ötesine Geçmek
SCD Type 2 uygulaması — "Müşterinin e-postası değiştiğinde yeni kayıt ekleyen ve eski kaydı end_date ile saklayan SQL'i yazın."
Sınır koşulları olan window functions — Sessionization, önceki null olmayan değeri bulma, sıfırlanan kümülatif toplamlar. LEAD(), LAG(), DENSE_RANK() kolay kısımdır; edge case'ler insanların başarısız olduğu yerdir.
Incremental load mantığı — "updated_at timestamp'ını kontrol edin" başlangıç noktasıdır. Kayıtlar silinirse ne olur? Kaynak geçmiş verileri geri doldurursa ne olur?
Sorgu optimizasyonu — Explain planlar, partition pruning, CTE'nizin neden beklenenden yavaş olduğu.
Data Pipeline Mülakat Soruları: Schema Evolution Tuzağı
"Sürekli değişen API'lerden veri çeken ETL pipeline'ında schema evolution'ı nasıl ele alırsınız?"
Güçlü bir yanıt şunları kapsamalıdır: geriye dönük uyumlu vs. kırıcı değişiklikler, format seçimleri (Avro, Protobuf vs. JSON), schema registries ve contract değişikliklerini downstream tüketicilere iletme.
Idempotency: "Pipeline'ınız iki kez çalıştırılmaya güvenli mi?"
Late-arriving data: Watermarks, sıra dışı event yönetimi, yeniden işleme stratejileri.
Orchestration hatası: "Airflow DAG'ınız 7 adımdan 4. adımda başarısız oluyor. Verilerinize ne olur?"
Gerçek zamanlı AI önerileriyle pratik yapın. AceRound AI, yanıtınızın ortasında doğru çerçevelemeyi sunar. aceround.app
Apache Spark Mülakat Hazırlığı: Job'ım Neden Yavaş?
"Spark job'ınız 45 dakika yerine 3 saat alıyor. Bunu teşhis edin."
Sistematik yaklaşım:
- Spark UI'ı kontrol edin — hangi stage yavaş
- Data skew — bir partition verinin %90'ını mı işliyor
- Shuffle işlemleri — gereksiz yeniden shuffle'lar var mı
- Kaynak yapılandırması — executor memory, GC baskısı
- Caching stratejisi — aynı DataFrame yeniden hesaplanıyor mu
Temel konular: broadcast join threshold, repartition vs. coalesce, executor vs. driver OOM, watermarks.
dbt Mülakat Soruları: Modern Stack'in Sinyal Noktası
Incremental modeller: append vs. merge vs. insert_overwrite stratejileri.
Test stratejisi: Schema testleri vs. data testleri, referential integrity.
Kırıcı değişiklikler: "Bir upstream tablo bir kolonu yeniden adlandırırsa dbt projenize ne olur?"
AI Mülakat Copilot'u Canlı Data Engineering Mülakatlarında Nasıl Yardımcı Olur?
Statik hazırlık kaynakları sizi mülakattan önce hazırlar. Performans açığı canlı oturum sırasında ortaya çıkar.
AceRound gibi AI araçları mülakat sırasında çalışır — schema evolution ayrıntılarını veya Spark yapılandırma parametrelerini unuttuğunuzda gerçek zamanlı olarak bağlamı ortaya çıkarır.
Pek çok Türk teknoloji profesyonelinin Kariyer.net'in ötesine geçerek Avrupa ve ABD şirketleriyle video üzerinden görüştüğü günümüzde, bu tür araçlar İngilizce mülakat ortamındaki iletişim boşluğunu kapatmaya yardımcı olabilir.
Dürüst bir not: Bilginin yerini tutmaz. Baskı altında bildiğinizle dile getirebildiğiniz arasındaki uçurumu azaltır.
Sık Sorulan Sorular
Data engineer mülakatlarında en sık hangi konular sınanır? SQL, pipeline mimarisi, Spark performans ayarı, dbt/Airflow/Kafka araçları ve davranışsal/sistem tasarımı.
Spark bilgisi zorunlu mu? İş ilanlarının %38.7'sinde yer alıyor. Dağıtık hesaplamaya sahip roller için neredeyse zorunlu.
Data engineering mülakatı yazılım mühendisliği mülakatından nasıl farklıdır? Daha az algoritmik kodlama; daha fazla pipeline sistem tasarımı, veri modelleme, dağıtık sistemler.
Prodüksiyonda dbt kullanmadıysam nasıl hazırlanırım? Snowflake veya BigQuery ücretsiz katmanında küçük bir proje oluşturun. Incremental modeller ve testlere odaklanın.
Data engineering mülakat hazırlığına yardımcı olan AI araçları nelerdir? AceRound AI, canlı mülakatlar sırasında beş alanın tamamını kapsar. SQL pratiği için StrataScratch ve DataLemur.
Yazar: Alex Chen. Kariyer danışmanı ve eski teknoloji şirketi işe alım uzmanı. İşe alım tarafında 5 yıl geçirdikten sonra adaylara yardım etmeye yöneldi. Ders kitabı tavsiyesi değil, gerçek mülakat dinamikleri üzerine yazar.
İlgili Yazılar

Belirsizliği Nasıl Yönetiyorsunuz? Gerçekten İşe Yarayan Mülakat Cevabı
'Belirsizliği nasıl yönetiyorsunuz' sorusunu Netleştir-Çerçevele-Karar Ver-İlet çerçevesiyle yanıtlayın; teknoloji, danışmanlık ve girişim rolleri için örnek cevaplarla.

İlk 90 Gününüzde Ne Yaparsınız? Daha İyi Bir Yanıt Verme Yolu
Genel 30-60-90 günlük plan şablonunun neden artık işe yaramadığı ve ezberlenmiş bir metin yerine ilana özgü, canlı bir yanıtın nasıl kurulacağı.

Bir Sonraki İşinizde Ne Arıyorsunuz? Ezber Değil, Gerçek Bir Yanıt
Görüşmeciler neden bir sonraki işinizde ne aradığınızı sorar, genel 'gelişim ve kültürel uyum' yanıtı neden yetersiz kalır ve gerçekten somut bir yanıt nasıl kurulur.